

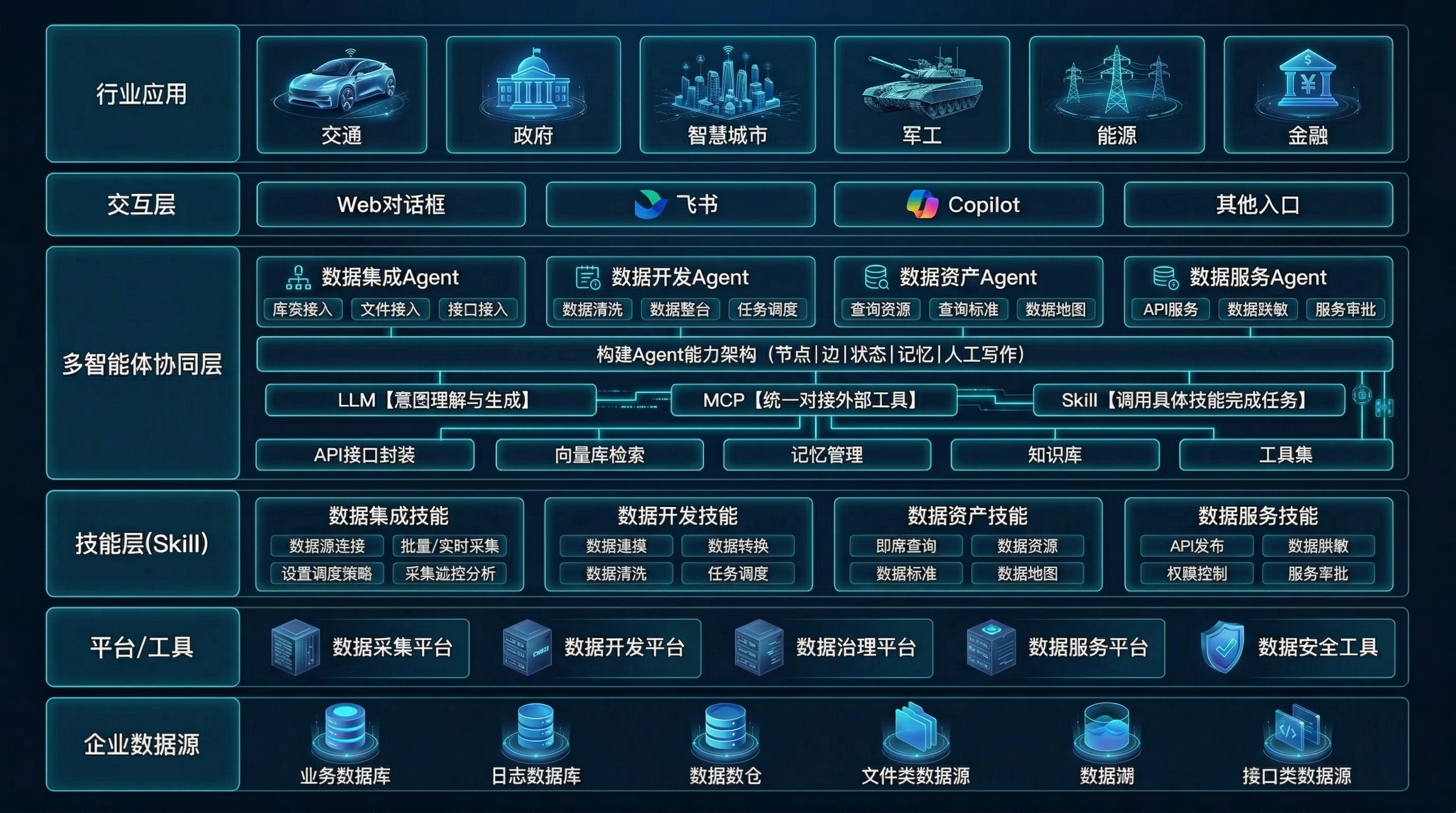
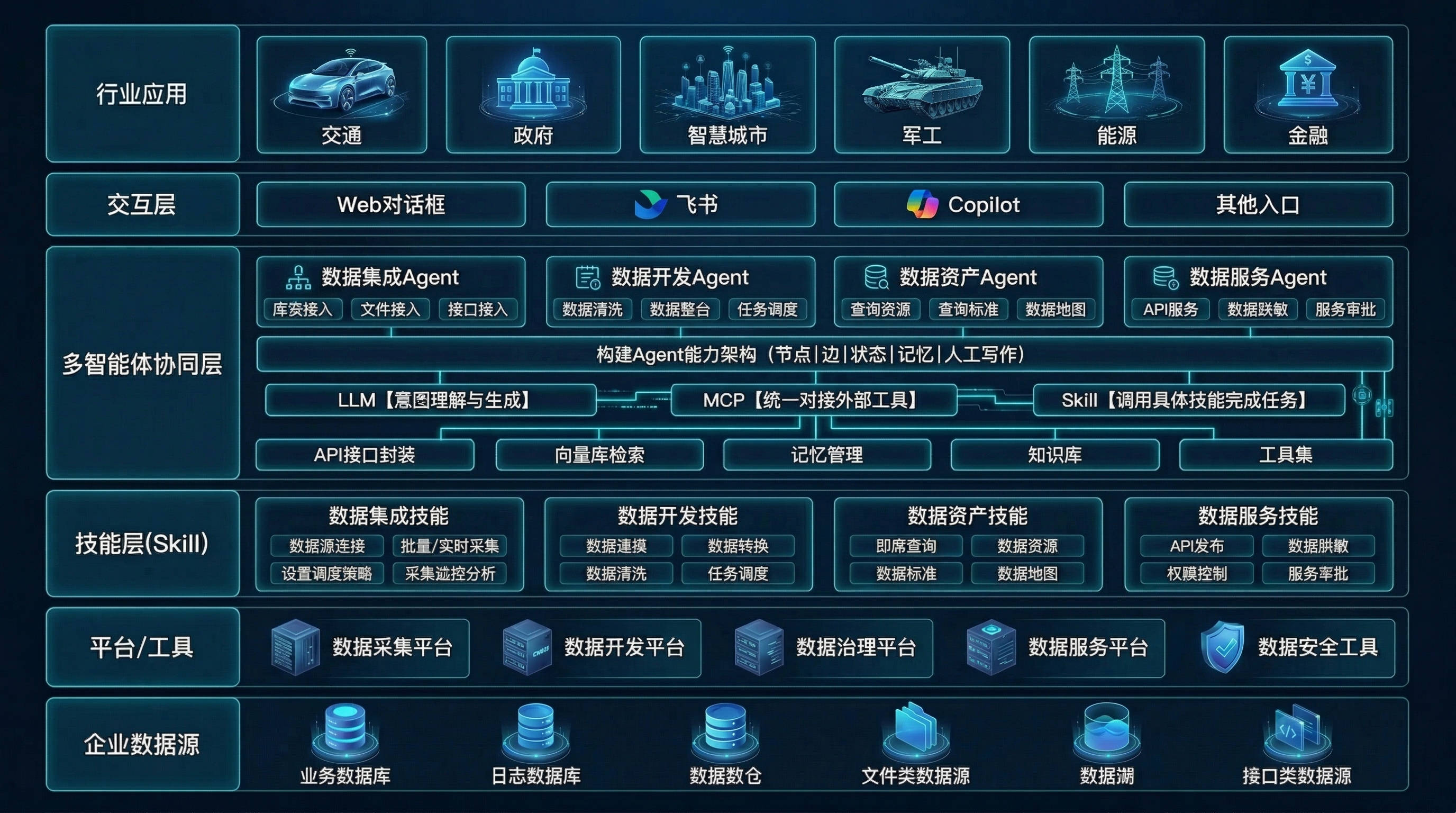
多模态数据主动集成与治理
对PDF 扫描件、图片、音视频等非结构化数据的主动感知、识别与特征提取能力。
Agent 能够自主生成并配置完整的数据采集、处理与同步任务链。无需人工编写脚本配置界面,实现 “一句话完成复杂数据管道的构建与调度” 。
针对 PDF、Word、扫描件、图片、音视频等非结构化数据,DataSphere AI内置 OCR、语音转写、多模态大模型等能力,可自动提取文本、表格、实体、语音内容及图像元数据,并统一治理为结构化、可检索、可血缘追溯的标准化资产,帮助企业将长期游离于治理体系之外的“暗数据”纳入统一资产管理。
针对字段中文名称缺失、业务定义不清、分类不完整等问题,DataSphere AI基于大模型上下文推理能力,自动补全字段名称、业务定义、数据分类及语义信息,推动数据目录从”可见“走向“可懂”。数据目录完整度可提升至85%以上,数据科学家找数时间缩短60%。
DataSphere AI将AI深度嵌入数据开发流程,支持 SQL 生成、脚本编写、逻辑解释、规范检查、任务排错与代码优化,帮助开发团队提升效率、缩短交付周期、降低人工编码错误,构建更高效、更稳定的数据开发体系。
通过规则引擎与 AI 识别相结合,DataSphere AI实现数据质量问题的自动发现、自动预警、自动归因与自动修复建议,推动质量治理从人工巡检走向持续自治,帮助企业更早发现问题、更快完成闭环,持续提升数据稳定性与业务可信度。

DataSphere AI支持对结构化、半结构化、非结构化数据进行统一扫描,可识别身份证、银行卡、病历等 100+ 类敏感信息。平台识别准确率可达 95% 以上,误报率控制在 5% 以内,分级分类效率提升 10 倍以上,有效支撑企业数据安全与合规治理。
基于表结构、历史文档、字段语义和业务术语,DataSphere AI可自动生成数据标准、指标定义和命名规范,并支持标准落标、偏差识别与一致性检查,帮助企业降低标准建设成本,提升标准制定、推广和落地效率。
DataSphere AI基于 AI 自动解析字段级数据血缘,在上游表结构或字段逻辑发生变化时,可秒级生成下游报表、应用和模型的影响地图,帮助企业快速评估变更范围、识别潜在风险,降低系统性影响和运维成本。
面向数据服务供给场景,DataSphere AI支持用户通过自然语言直接描述需求,平台自动完成意图解析、资产匹配、逻辑组装与参数映射,并一键发布为标准 RESTful API ,同时自动附加鉴权、限流、审计日志等治理策略,极大缩短数据服务交付周期,提升数据资产复用效率。

百余细分行业共同选择

线上线下产品培训

故障处理及系统升级

24H管家式服务
7X24小时服务
专家一对一持续业务保障
响应零延迟标准化实施
全智能实时监控强大的交付能力
实现客户价值

 版权所有 ©成都四方伟业软件股份有限公司
蜀ICP备14024109号
版权所有 ©成都四方伟业软件股份有限公司
蜀ICP备14024109号








